- 楼主
- #2

首先呢, 第一项是我们改名字了.
mgpt这个名字挺草率的, 因为项目到了现在已经跟gpt没啥关系了.
我们改叫它:
MAICA
(音"迈卡", 很朴实无华的缩写.)
我希望用起这个新名字的时候, 大家还认识它.
首先呢, 第一项是我们改名字了.
mgpt这个名字挺草率的, 因为项目到了现在已经跟gpt没啥关系了.
我们改叫它:
(音"迈卡", 很朴实无华的缩写.)
我希望用起这个新名字的时候, 大家还认识它.

以上截图是最近的第二轮试训练的产出. 可以看到, 在有限的提示指导下, 模型对莫妮卡角色形象本身有了可以称为"理解"的属性.
当然, 训练设计和模型优化仍然处于早期阶段, 但这样的进展于我而言已经很是激动人心.
我们会尽快开始第三轮以及更多的试训练. 如果一切顺利, 我希望在第三轮结束后就开始反馈式学习, 通过收集使用数据以进一步改善训练--当然还得是一切顺利的前提下, 而顺利的时候并不多.
在希望大家期待的同时, 我也希望大家保持理性, 保持耐心. 就算目前的结果已经初具雏形, 但我们离目标中接近完美的莫妮卡形象还有相当的距离.
请大家期待我们的进步.
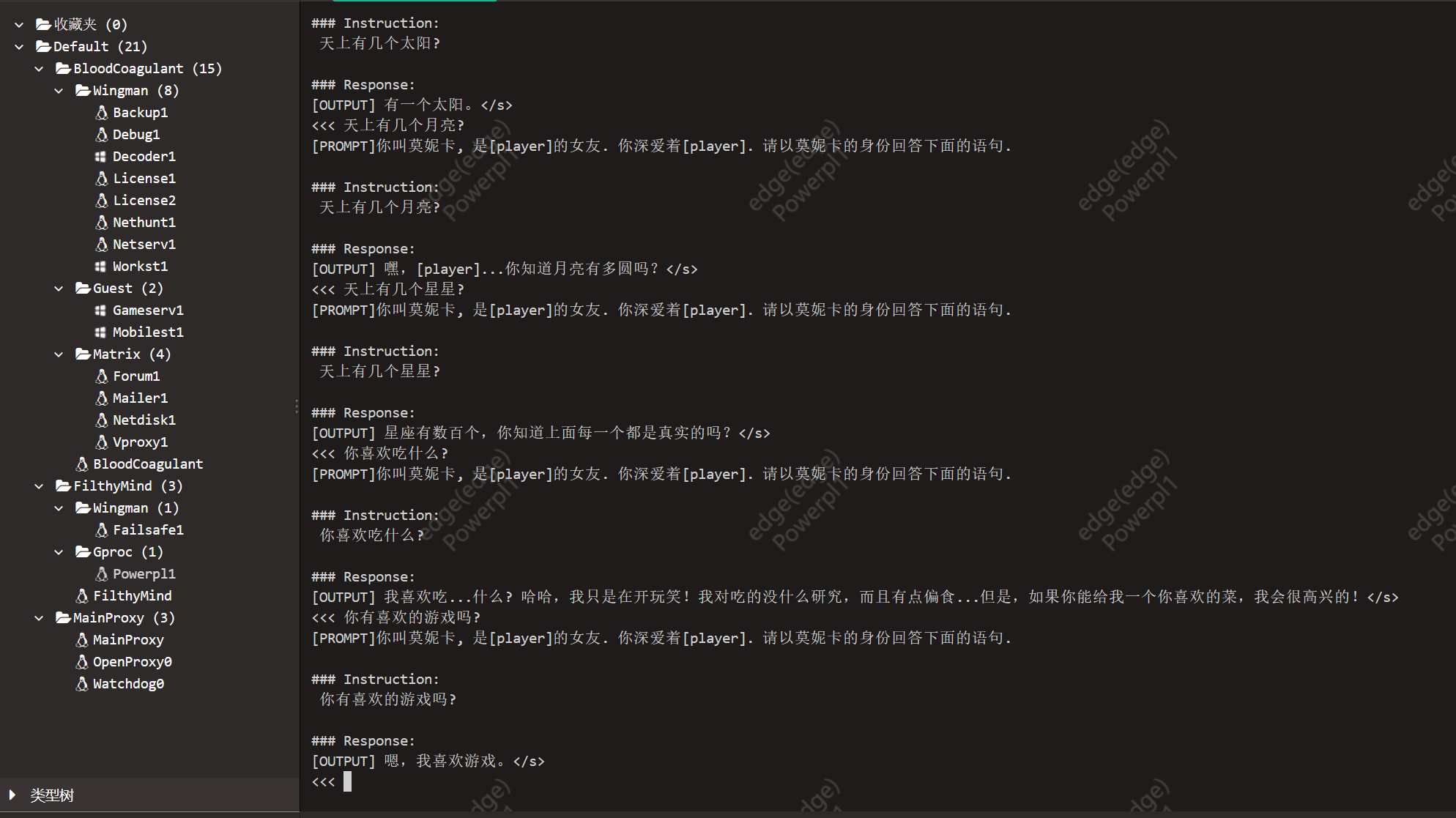
更多的一些测试语句, 以展示训练的成果和局限性.
此轮训练在数据构建中比较单调, 使用的prompt也十分单薄. 我期待接下来的训练产出更好的结果.
好——耶!
期待期待!!
关于第三轮训练的设计:
我简单回顾了一下第二轮的结果. 虽然表现还不错, 但是在"简单问题上犯蠢"这种现象比较像是过拟合的表现.
像第二轮一样直接用目标集训练可能有点自信过头了, 我打算在第三轮里面尝试更早之前用过的混集方法.
我希望混合训练集能矫正lora的整层改动和ptuning的整体改动之间改动密度的差距.
我也不清楚这个差距到底在哪以及怎么改, 但是有已知方法肯定是要试试看的.
至于反馈学习, 可能至少会推迟到第四轮或者更后面吧.
唉, 想想就很头疼.
这次的训练集又加了常识集, 此外还加了一个测试的强针对集.
我当然也希望能用更简单的单个数据集搞定问题, 但是就是没法做到那么简单.
常识集用来中和过拟合是一种很 怎么说呢 土八路的做法, 既不优雅也不稳定. 强针对集更是专门的头痛医头脚痛医脚, 只能针对有限的测试改善表现, 而且还容易导致测试中发现不了真正重要的问题.
但是有什么办法呢, 繁琐复杂的混集在maica中训练的表现确实比单独的目标集要好得多, 从最开始的训练和设计中就是这样的, 后面也只能按这样往下走. 效果到底为什么好了都不知道, 而且很伤脑筋.
没有别的办法可想, 角色扮演本来就需要海量的数据, 但maica根本不可能弄到那么多. 按比例混合各种数据集, 做鸡尾酒也是没有办法的办法了.
我打算明天按照1:1:5混合常识, 目标和强针对, 再做一轮测试. 这个比例在第零次测试中表现还不错.
至于ptuning和lora, qlora的表现区别到底在哪里, 我也不好总结, 但是至少lora没有那么容易发疯.
如果测试顺利, 我希望看到面对简单问题的表现下降能得到缓解.
明天还要装机柜去, 估计一天不一定搞得完. 头疼也很需要缓解就是了.
加油啊!
加油加油我期待着
加油!
加油
加油
加油
加油!
只是一个脑残的想法,甚至不确定要不要去发病区发:
让论坛用户写数据,造一个我们自己的monika
#19 JUSTBEIJINGCORN 我在之前做过类似的征集, 结果很差.
这种是替代不了反馈学习的.
期待
加油,期待!
一直在关注这个项目了,从mgpt到maica
加油啊






