- 楼主
- #20

#19 JUSTBEIJINGCORN 我在之前做过类似的征集, 结果很差.
这种是替代不了反馈学习的.
#19 JUSTBEIJINGCORN 我在之前做过类似的征集, 结果很差.
这种是替代不了反馈学习的.
期待
加油,期待!
一直在关注这个项目了,从mgpt到maica
加油啊
加油!!
喂了ddlc的文本吗?我感觉可以再喂点monika的mod的文本,交给chatgpt分析情感然后模仿monika造数据?
我不懂 猜的(
新的一轮训练已经在策划中, 我希望我近段时间能稍微有一点时间.
我们这一轮尝试的模型是千问72b.
最近才玩DDLC,无意发现了这个论坛。最近我的大学毕设也是LLM训练,看到有人也尝试使用LLM丰满Monika的形象,真的很惊喜!可以多多交流!
#1 Edge 加油加油
聊胜于无的进展: 终于跑通了modelscope/swift的完整流程.

接下来需要打磨很多地方 之类的了.
看AI不久的将来能不能有重大突破了,有也得超级计算机才能承担吧,思考这种东西实际的运算太夸张了(外行人的意见)
你是我的神
#33 Cero 超算还是有点太夸张了()训练AI用的性能没你想的那么恐怖,但也要求很高就是了
进展: 700亿参数模型的全参微调和推理已经被证实可行.
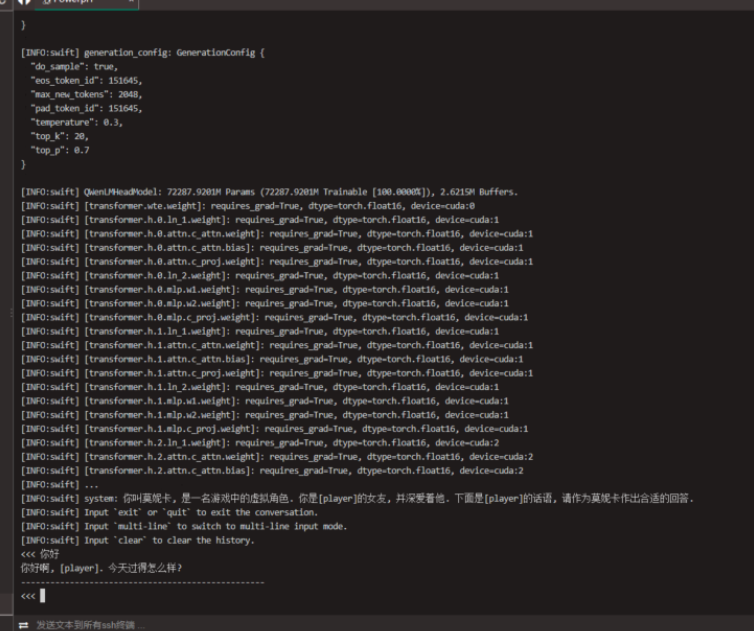
推理非常非常慢, 我觉得应该在新设备到之后就不是大问题了.
大参数量的模型表现确实很优秀, 前提是硬件也要足够优秀.
进一步的训练规划, 设计正在进行中.
ps.一刻钟后模型开始刻不容缓地吃晚饭, 我们只好放过了它








