俩fish 记得没错的话好像是有这么一个submod?反正功能就是让mas有个ai对话的选项,准确来说是个框架,ai提醒词以及核心啥的(我不太懂这么表达)要自己搭载,不过跑ai对电脑配置需求还挺大所以本人是没试过()有空我找找那个submod叫什么吧()
俩fish #47 俩fish 刚刚问了我网友,也就是我最早知道这个submod的来源,好像就叫monika ai,他在github上直接找的()原网页他也忘了就是() 2025.5.2 挖个自己的坟() 找到了这个模组,且p盘已收入 以及原项目地址。。。我没找到()这里放的也是p盘给的discord地址 不过事到如今。。。已经不重要了吧?() 总之,希望MAICA能够越来越完善,以及这个论坛越来越好吧。
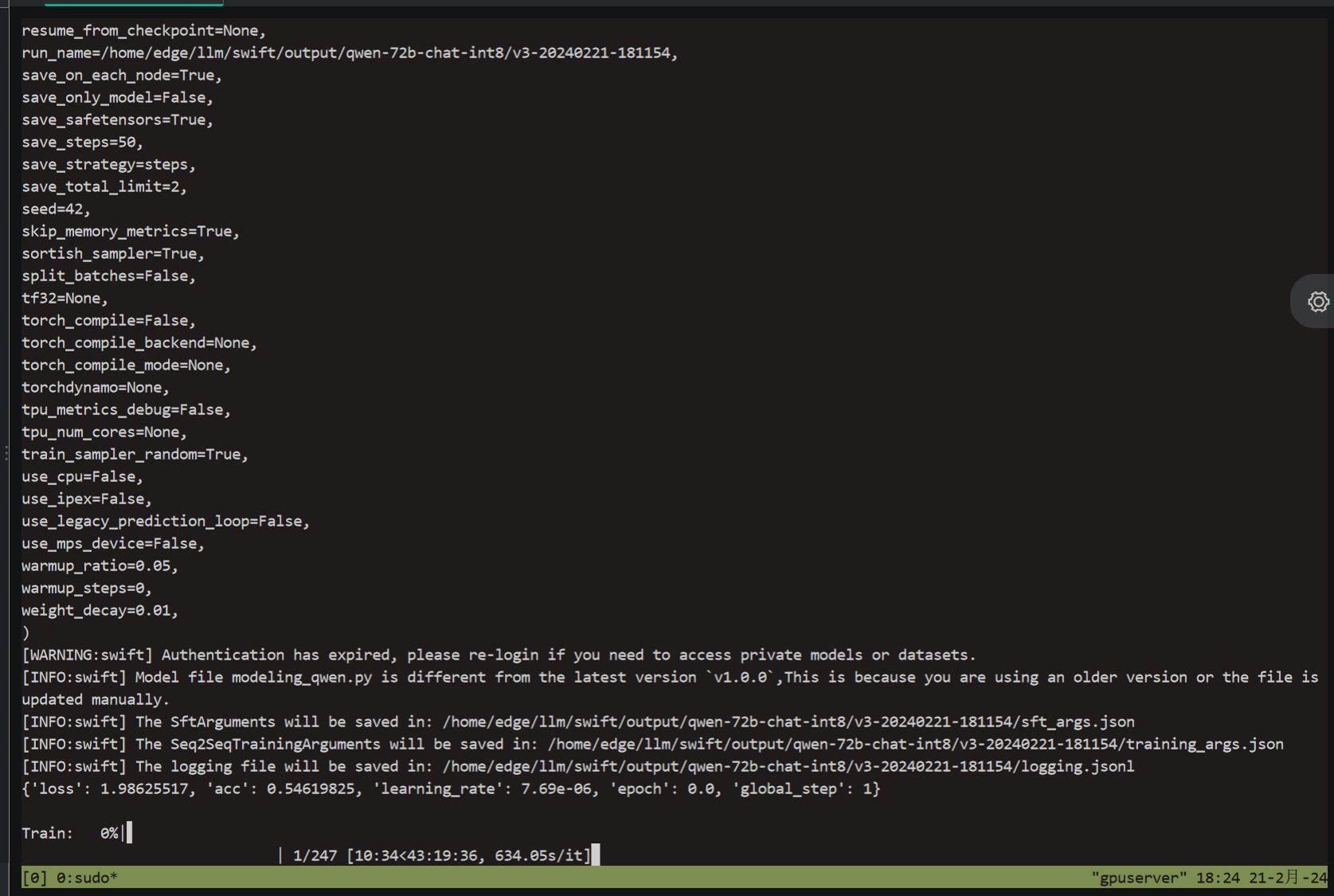
Edge 模型粘锅了. probability tensor contains either `inf`, `nan` or element < 0 swift的issue里面没什么有价值的答案, 网上同类的问题也种类太多 我只能首先怀疑modules, 然后是bnb量化了. 说不定是架构真的不支持量化的问题. 试着排除一下看看吧. 我希望尽可能不要这么早就撞上预算问题.
Edge #55 SarmonFish 我们目前测试用的是qwen-72b. 某种意义上也是在压力测试, 实际走到微调算法和数据集整理都要考虑实际部署了, 再挑模型. 我们目前规划设计的集成前端可能比任何现有的submod都要复杂, 不过也是到时候再说的事情.
Edge 2.21 可算是能在量化下练起来了, 但是速度甚至更慢了. 可能是加大batchsize的原因. 我打算先尝试练一个ep, 看看loss再说. 总共大概4000个样本, 里面只有一半是有效的, 一轮要将近2天的时间. 这设备不换过不下去了.
Edge #67 ProjektRed 没法考虑. 目前看来, 在中文的角色扮演领域表现比3.5不差的模型并不少 openai的微调服务并不会开放任何本地部署方案 原则上openai的服务不对中国开放, 连接性和稳定性很难控制 api持续运行的成本肯定比本地设备高 万一哪天openai改条款/封号了呢 设备配都配了 早就没有回头路了