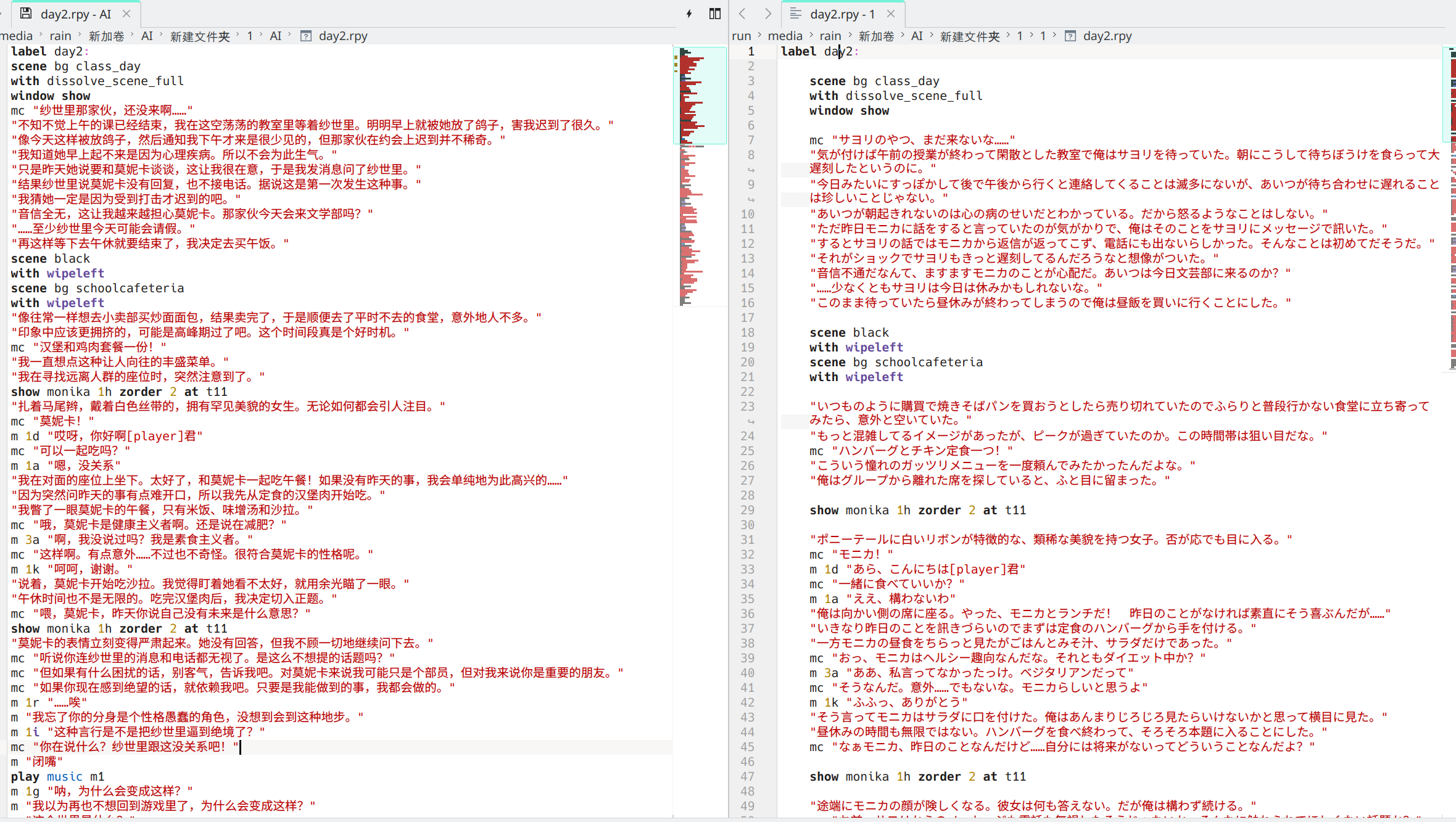
今天抽空手动处理翻译好的文件的时候,有点厌倦了反复对比恢复格式。做了个小工具来简化流程。
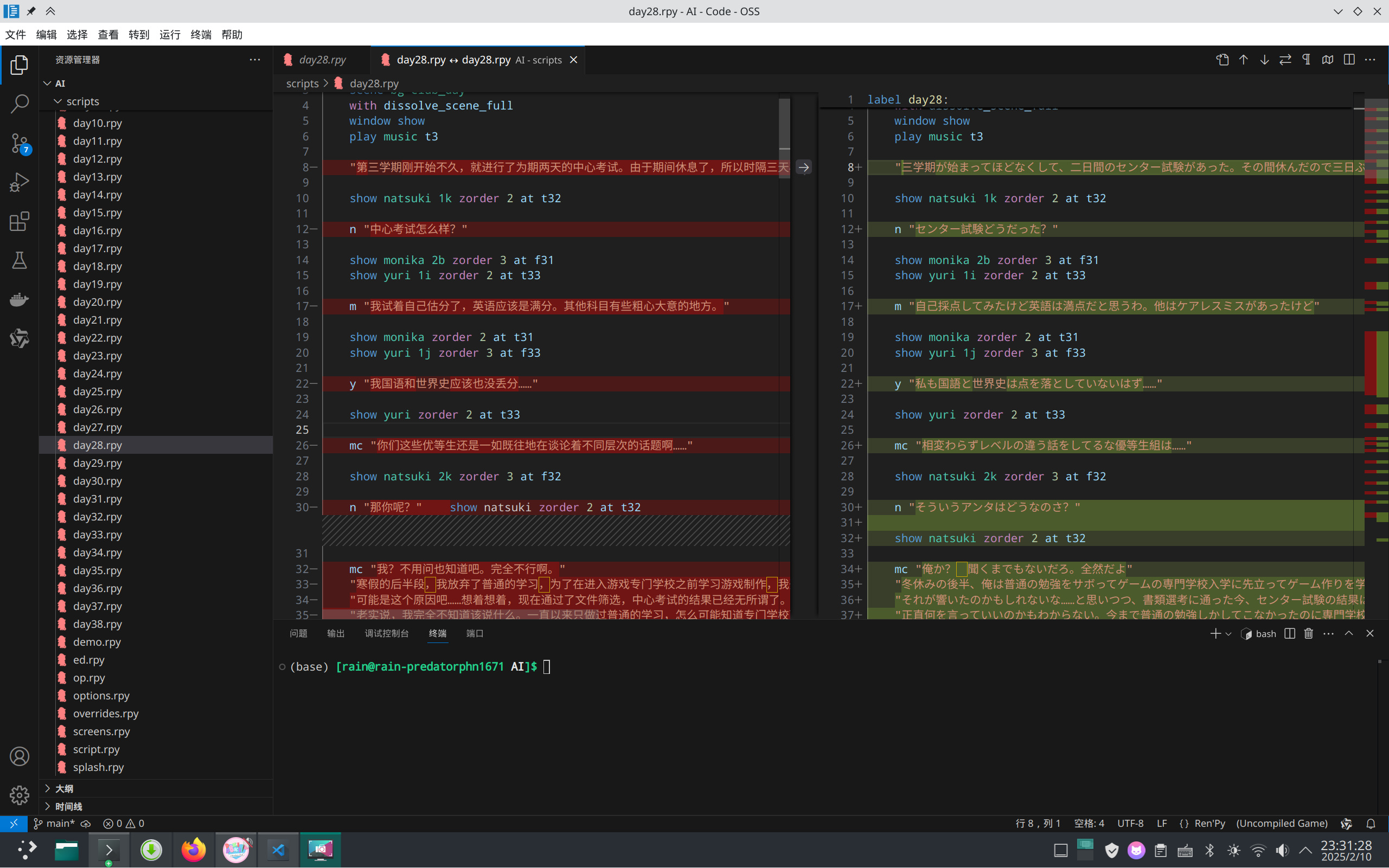
具体来说,需要有mod文件的译文和原文。它会检查两者各有多少个被“”围住的字符串,也就是一般情况需要翻译的部分,如果数量相同,就会提取译文所有在“”内的文本,按顺序放在原文的位置上。第一个译文到第一块原文的位置,依次类推。
在译文稍加处理后(去掉可能存在的重复段落,或者“”被改为「」这种有相似功能的符号),基本上可以正常运行。一次性恢复原格式。
注意,若译文顺序颠倒错乱,就算使用了也还是颠倒错乱的。但一般大模型返回的文件应该不会有这种问题。大多数情况只是缩进和换行错了。
使用方式为终端:python rpy格式修复.py 原文件 翻译文件 输出文件。记得加路径。
https://disk.monika.love/s/pb7f9