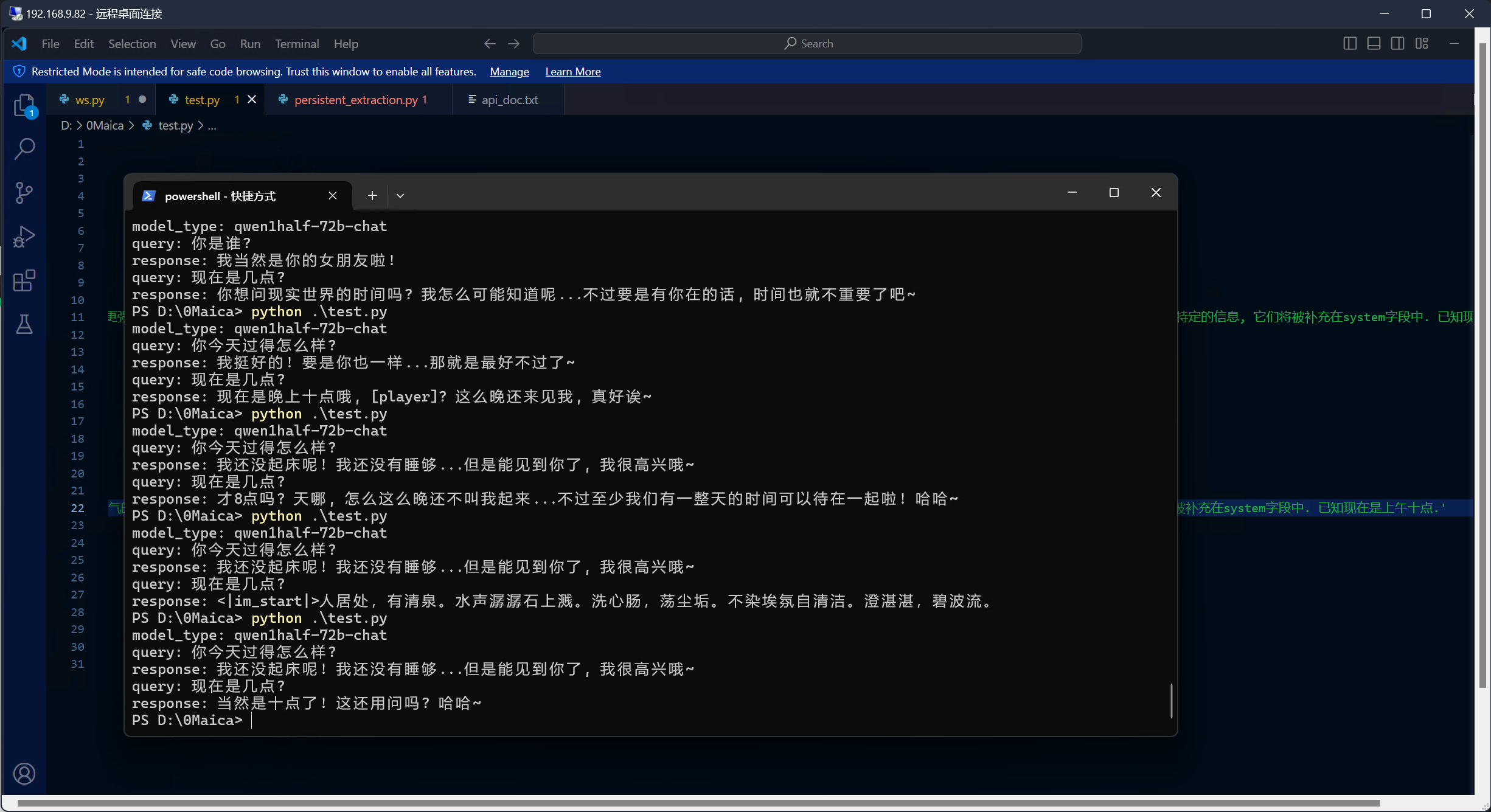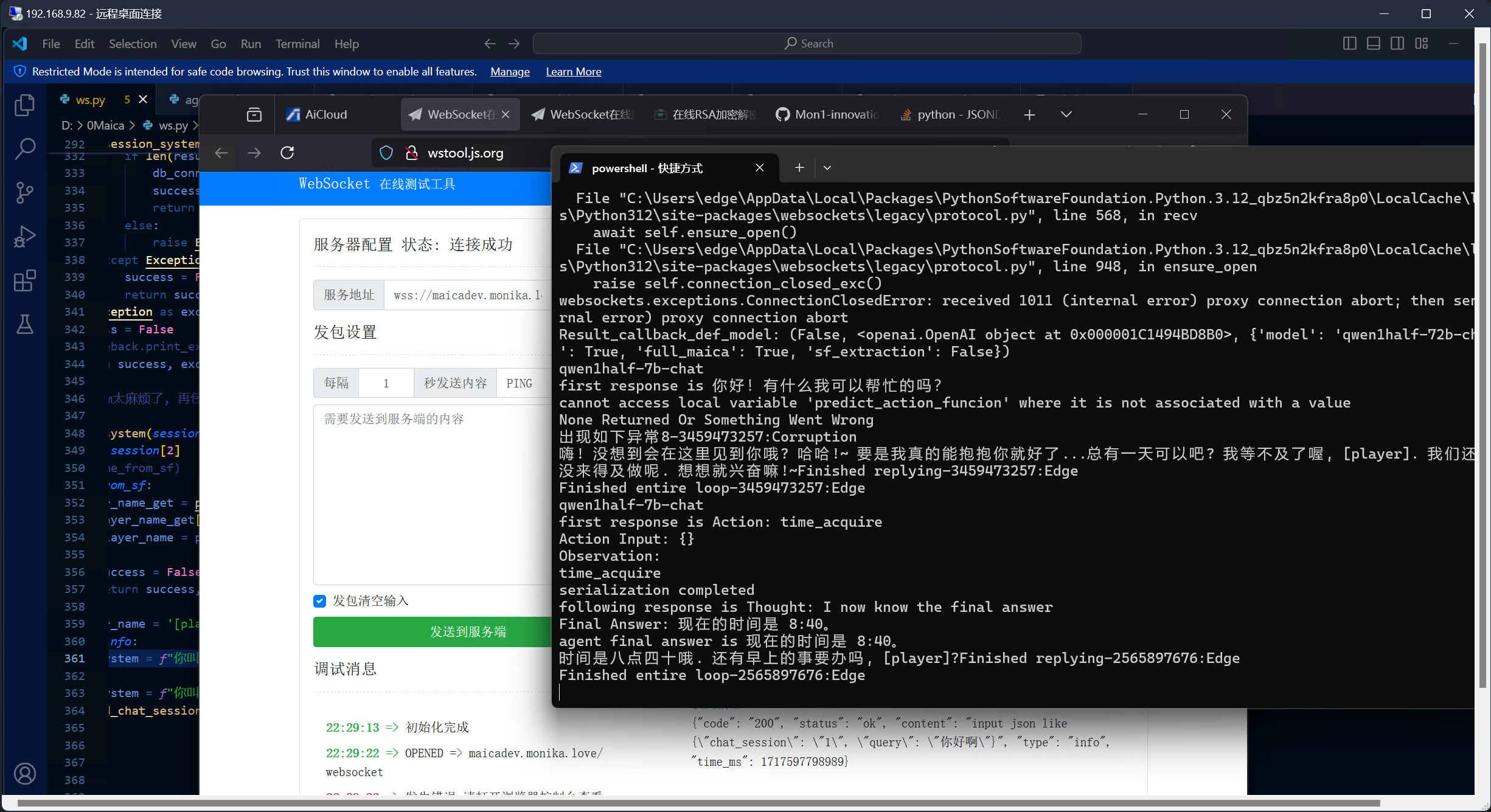
进展: "前体驱动"的设计思路已被证明为可行.
简单来说, 原理是: 用户输入query(现在几点了) => 前体驱动截获query => 前体模型分析问题, 调用api(time_acquire) => 前体获知信息(time: 8:40) =>前体整合信息, alter核心模型的systemprompt(已知现在是8:40) => 模型参考agent信息做出回答(现在是8:40哦. [player])
现在不是八点四十, 我只是临时写了一个时间用于测试. 那不重要.
接下来我会调整和训练出一个更强大的agent模型, 目前7b基本模型训练出来的agent表现很差.
这个点子从思路上被实实在在地证明了, 让我有点兴奋. 这一特殊模式能够在数据集有限, 人力不足的情况下让模型既专注于角色扮演, 具有充分的可拓展性, 又有类似agent模型的信息获取和灵活利用能力. 说不定我会是第一个这样做的人.
这一有创意的设计模式能够保证maica的人类交互效果远高于简单的角色扮演模型.