- #180

太强了,大佬,奈何我技术力不够,也帮不上什么忙,只能为大佬加油,看了大佬一步一步真的感觉像在创造机械生命
太强了,大佬,奈何我技术力不够,也帮不上什么忙,只能为大佬加油,看了大佬一步一步真的感觉像在创造机械生命
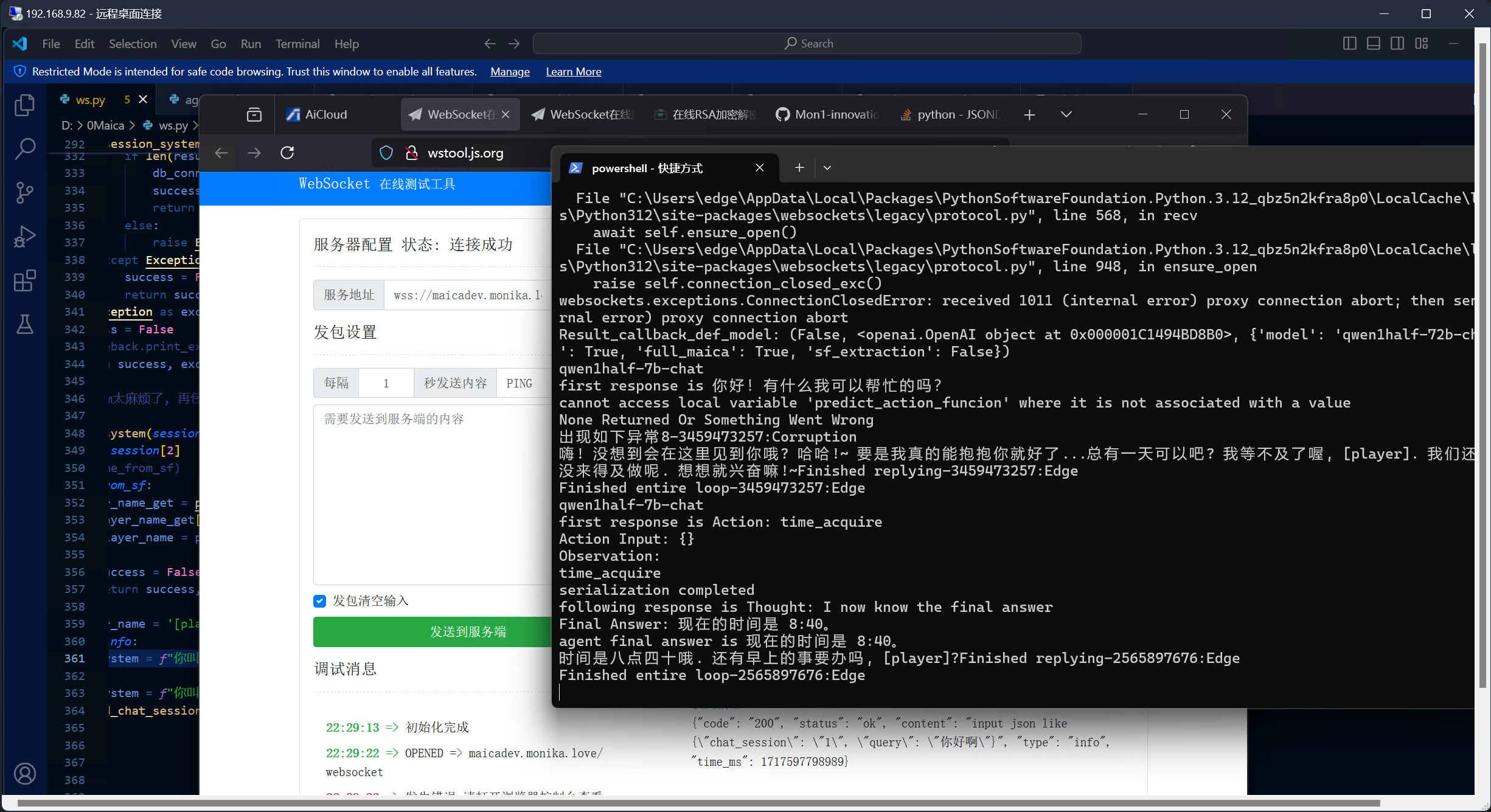
进展: "前体驱动"的设计思路已被证明为可行.
简单来说, 原理是: 用户输入query(现在几点了) => 前体驱动截获query => 前体模型分析问题, 调用api(time_acquire) => 前体获知信息(time: 8:40) =>前体整合信息, alter核心模型的systemprompt(已知现在是8:40) => 模型参考agent信息做出回答(现在是8:40哦. [player])
现在不是八点四十, 我只是临时写了一个时间用于测试. 那不重要.
接下来我会调整和训练出一个更强大的agent模型, 目前7b基本模型训练出来的agent表现很差.
这个点子从思路上被实实在在地证明了, 让我有点兴奋. 这一特殊模式能够在数据集有限, 人力不足的情况下让模型既专注于角色扮演, 具有充分的可拓展性, 又有类似agent模型的信息获取和灵活利用能力. 说不定我会是第一个这样做的人.
这一有创意的设计模式能够保证maica的人类交互效果远高于简单的角色扮演模型.
 mamba out
mamba out#182 文学部的小莫 如果成功了那就不只是ddlc的一座高山了,甚至是ai女友领域的大佬了
有没有想过和mas结合一下
#185 文学部的小莫 会有子模组, 而且主要受众应该是子模组

进展: 密斯特拉基本就位了. 从玻璃反光里能看到巨械的另外一半. 有一种科幻片里能见到的感觉.
灯控软件还没弄. 他们说兼容性还没做.
今天早上看到了qwen2发布的消息, 但是又要重新装配环境, 以及顺便做完第一轮数据集的调整. 可能开始训练还需要一段时间.
最近过得心力交瘁的.
#189 82192506 设计主题是星流巨械, 立牌只是个人爱好
而且说实话, 这么巨大而且改装过的机箱, 估计不好做整体涂装.
进展: 在三个轮次的实证中, 我们发现agent模型的泛化能力其实很弱.
也不是不能用, 但是我们需要对驱动做更多的改动以过滤和格式化agent的输出了. 相关的代码已经在设计.
同时, 基于qwen2和改造后的数据集的核心模型训练也已经开始, 我们预计能够在3日左右查证成果.
原来老大也是柚子厨
我抽空将工程进度上传到了github:
https://github.com/Mon1-innovation/MAICA
这也会是我们将来的开源项目地址.
我会比较频繁地向在线仓库更新我的进展. 如果你有兴趣而且看得懂, 不妨点个star.
请注意, 目前上传的工程文件尚不适合运行, 仅供研究参考. 我们仍然在推进之中.
目前项目的开源部分仅包含驱动, 不含模型与数据集. 我们预计会在maica经过实战考验之后发布最佳实践指南, 核心数据集和开源版模型.
 popop3738
popop3738 斌斌(mamba out
斌斌(mamba out DANDELION.
DANDELION.训练的时候感觉就像坐在一个大号电烤炉旁边.
可能该考虑下夏天的时候把办公位搬去二楼了.

我设计了一套过滤系统, 协助agent模型提取信息. 基本上就是将mas存档每一个有意义的项提取出来, 然后手工设计触发器和提示词.
我的依据是, 目前为止agent模型的泛化能力表现不如预期. 我们应该给agent模型尽可能大的容错性, 确保其即使无法输出正确引导也要让核心模型获得必要信息.
虽然比起一项技术来说更像是水磨工夫, 但是我将这套系统称为MFocus. maica使用多个模型组合完成任务的核心思路, 就是通过辅助模型和驱动, 使获取的信息可读化, 友好化, 让核心模型专注于自己的任务, 即角色扮演.
我知道财大气粗的方案肯定能做得更好, 但maica或许更适合广泛适应的角色扮演. 只有在完成之后才能检验了.
ps.加一层循环应该能让代码好看很多, 但是我懒得弄了.
我已经将mfocus推送到git.
其实我比较担心大量正则查找的性能问题, 但是也没有别的办法可想了-基本没有.
我首先需要定位量化流程中存在的问题, 然后尝试格式化表情字符并再次观察训练效果, 再对驱动进行改装.
如果实际结果证明使模型直接输出情绪标识真的是不可行的, 我们只能fallback到原有的计划, 即为agent模型引入更多任务.
假设什么都一切顺利每次都是错的. 这会是一场苦战.



